Cet article est une retranscription d'un talk donnée à ParisJS le 3 Février 2021
J'imagine que le terme "type algébrique" peut en effrayer certain·e·s, mais on va essayer de l'aborder sous un angle plus pratique que théorique.
Les problèmes d'interface courants

L'image ici est assez connue, elle est tirée de Windows XP, où un message d'erreur nous indique fièrement "Succès !".
Ce genre de comportements étranges, on cherche à les éviter et on investit en général beaucoup de notre energie à ça, que ce soit au travers de tests, de QA ou d'autres stratégies.
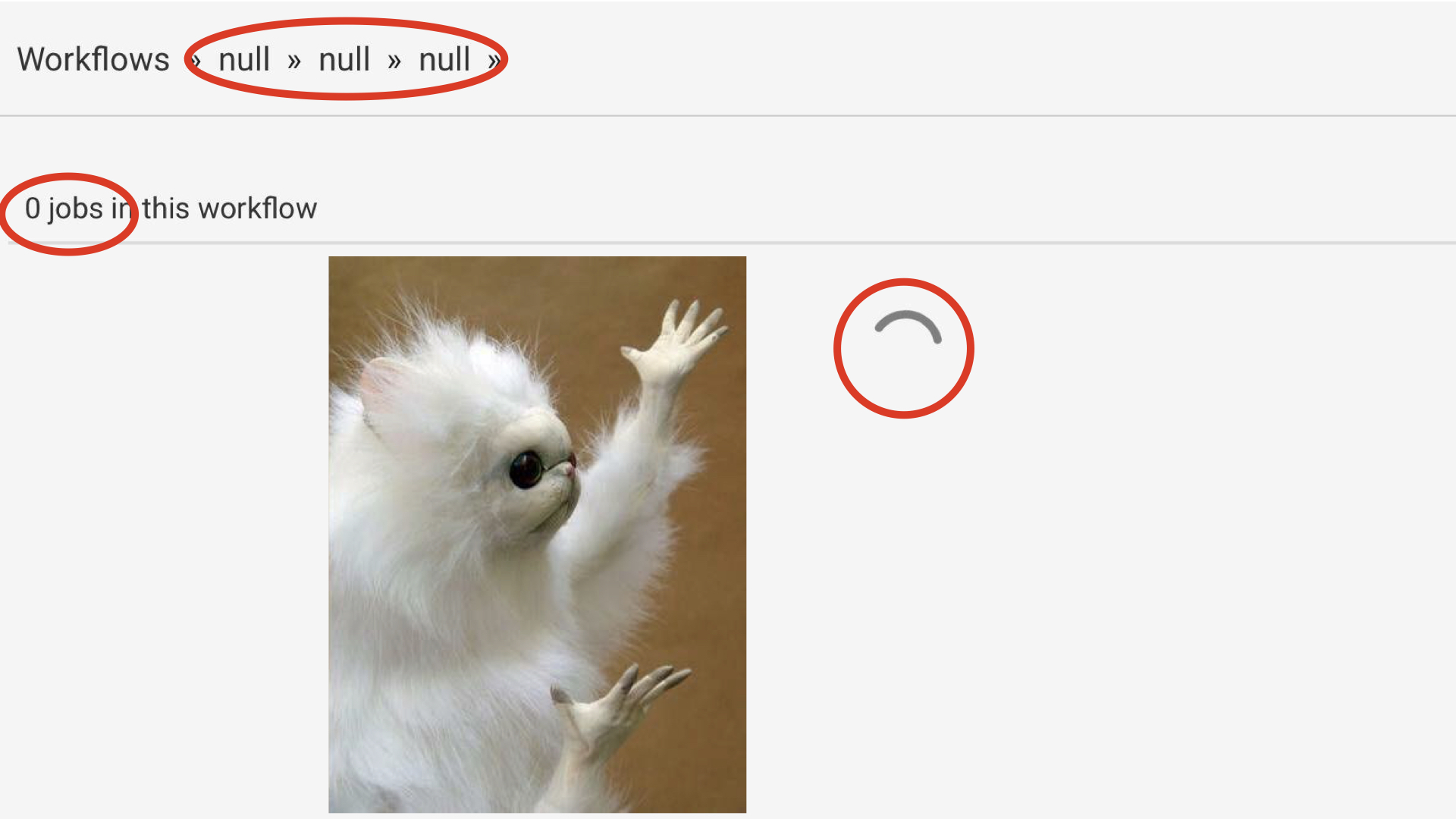
Pourtant ces cas étranges reviennent toujours à la charge.
Si on regarde bien ce dernier screenshot, on se trouve dans un état de chargement (il y a un loader), mais on a null affiché 3 fois dans le fil d'ariane et 0 job dans le résumé. Pourtant lorsque le chargement se termine, ces valeurs sont remplacées par les bonnes.
Visiblement ce qui se passe est que les différents bouts de la page n'ont pas tous été prévenus que c'était en train de charger.
Ça peut sembler trivial, mais ça peut également être symptomatique d'un problème assez grave: l'information présentée à l'écran est erronée, plutôt qu'afficher "je ne sais pas encore", elle affiche un résultat faux. Imaginez ce genre de problèmes dans une application utilisée dans un hôpital, si pendant un chargement long vous affichez qu'un patient reçoit 0 traitement, ça peut vite influencer une mauvaise prise de décision pour les médecins, et ce sera le software qui sera responsable.

Il arrive aussi que des erreurs fatales se glissent dans votre application, à cause d'un oubli, d'une erreur dans le code ou d'un cas non prévu.
La plupart des symptômes tels que ceux qu'on vient de voir découlent de la manière de gérer 3 choses, et ces 3 choses on y est confronté dans virtuellement toute application avec une interface utilisateur.
- L'optionalité : la gestion de la présence ou non d'une valeur
- Le succès : la gestion d'une opération qui peut échouer
- Les requêtes : aller chercher de la donnée qu'on a pas encore
Gérer l'optionalité
Prenons l'exemple d'une montre connectée qui est en charge de tracker votre activité physique. Sur l'application de la montre dans votre smartphone, vous avez une vue avec un calendrier qui résume l'activité enregistrée.
Partons du principe que vous travaillez sur cette application. La team produit vient un beau jour et vous dit :
«On voudrait créer une notification push pour motiver les utilisateurs. La règle qui nous parait bien, c'est de l'envoyer aux gens qui au cours des 30 derniers jours ont:
→ un jour ou plus sans avoir porté leur montre
→ un jour ou plus avec une activité sous un certain seuil»
Ça tombe bien ! Pour faire votre calendrier vous avez déjà accès à un tableau qui contient l'activité des 30 derniers jours.
Dans ce tableau:
- Soit vous avez un objet avec les données du jour
- Soit vous avez
undefinedsi l'utilisateur n'a pas porté sa montre
let last30daysActivity: array<maybeActivity>
// no activity recorded for the day
undefined
// some activity
type dayActivity = {
calories: int,
workoutDuration: int,
standUpHours: int,
}
On va donc chercher dans notre tableau si un élément matche le prédicat qu'on nous a donné : on cherche au moins un jour vide ou avec une activité basse.
last30daysActivity.find(item =>
item == undefined || item.calories < 50
)
Puis on fait nos premiers tests et il arrive que ça retourne undefined. Mais ça veut dire quoi undefined ici ?
Est-ce que ça veut dire :
- Que la méthode
findn'a rien trouvé qui matche notre prédicat, auquel cas il ne faut pas envoyer de notification ? - Que la méthode
finda trouvé un jour vide qui matche, auquel cas il faut en envoyer une ?
Simplement à partir de cette valeur de retour, on ne peut pas savoir si on doit envoyer cette notification.
Pour comprendre pourquoi on se retrouve avec ce dilemme, il faut regarder la signature de la méthode find.
Elle prend un tableau d'éléments d'un type A, un prédicat, et elle retourne soit un élément de type A, soit undefined si aucune valeur ne satisfait le prédicat :
let find: (array<'a>, 'a => bool) => 'a | undefined
Mais si le type A en question comprend la valeur undefined, la valeur de retour peut être undefined dans deux cas :
let find: (
array<'a | undefined>,
('a | undefined) => bool
) => 'a | undefined | undefined
// ^^^^^^^^^ ^^^^^^^^^
On n'a aucun moyen de les distinguer ces deux cas . Les deux valeurs sont strictement identiques. undefined et null sont des valeurs substitutives : elles se substituent à la valeur en cas d'absence.
Une façon correcte d'identifier le cas dans lequel on se trouve serait d'utiliser findIndex, qui renvoie l'index du match, et -1 s'il n'en a pas trouvé. À partir de cet index on peut ensuite aller chercher manuellement la valeur dans le tableau.
let index = last30daysActivity.findIndex(item =>
item == undefined || item.calories < 50
);
if(index == -1) {
// not found
} else {
let item = last30daysActivity[index];
if(item == undefined) {
// found day without recorded activity
} else {
// found day with low activity
}
}
Ça fait quand même beaucoup de branches dans notre code pour une tâche censée être plutôt simple.
La plupart des langages fonctionnels typés n'ont pas de undefined, ou de null. Ils ont un type option (ou maybe).
type option<'a> =
| Some('a)
| None
Le type option est comme une boîte. Vous pouvez voir ça comme l'expérience du chat de Schrödinger : votre boîte a deux états possibles, soit elle contient une valeur, soit elle ne contient rien.
Au lieu de trimbaler une valeur ou son substitut, vous trimbalez une boîte qui contient peut-être une valeur.
Donc prenons l'équivalent de la fonction find en ReScript, elle s'appelle Belt.Array.getBy mais la fonctionnalité est la même :
last30daysActivity->Belt.Array.getBy(item =>
switch item {
| None => true
| Some({calories}) when calories < 50 => true
| _ => false
})
Si on regarde la signature cette fois ci, on voit qu'elle retourne une valeur de type option :
let getBy: (array<'a>, 'a => bool) => option<'a>
Et quand on remplace le paramètre par nos valeurs optionnelles, on se rend compte qu'au lieu de substituer la valeur de retour, on retourne une option d'option : on peut ranger des boîtes dans des boîtes.
let getBy: (
array<option<dayActivity>>,
option<dayActivity> => bool
) => option<option<dayActivity>>
En pratique, ça veut dire qu'on peut désormais distinguer précisément le sens de la valeur retournée, sans pour autant s'imposer des détails d'implémentation qui complexifient inutilement notre code :
None // No match
Some(None) // Found an empty day
Some(Some(x)) // Found a filled day
Gérer le succès (et l'échec)
Dans la plupart des langages, les échecs sont souvent représentés par des exceptions, des erreurs. On écrit des fonctions censées retourner un résultat, et on va court-circuiter l'exécution quand quelque chose échoue.
Dès lors, la signature de la fonction représente le cas où tout se passe bien, le happy path.
// BE CAREFUL!!!
// Throws an error
let f: 'param => 'success;
En revanche, connaître les cas d'échec, à moins d'écrire des annotations à la main ou de la documentation, est tout de suite moins évident parce que la manière de récupérer ces erreurs est de wrapper le code pouvant échouer dans un try/catch, à quelque niveau que ce soit au dessus de l'appel qui peut "casser".
C'est pas forcément idéal, parce qu'il faut souvent aller faire l'effort de regarder si l'erreur est traitée, et si c'est le cas à quel niveau de pile d'appel elle l'est.
try {
let x = f()
// The error might be thrown by `f`, but also from something
// `f` calls, somewhere
handleSuccess(x)
} catch(err) {
handleFailure(err)
}
Pour ces cas là, la plupart des langages fonctionnels typés ont encore une fois une alternative qui s'appelle le type result (ou either).
type result<'ok, 'error> =
| Ok('ok)
| Error('error)
Le type result est un autre genre de boîte, qui cette fois-ci contient soit un résultat (ou valeur de succès), soit une erreur.
L'énorme avantage est que votre fonction qui peut échouer va retourner une boîte plutôt qu'une valeur directement. Juste en regardant la signature de la fonction, vous savez si elle peut échouer :
let f: 'param => result<'success, 'error>;
Et pour extraire le résultat qui est peut être dans la boîte, vous êtes obligé·e de gérer le cas d'erreur : plus de surprise sur l'endroit où il est traité.
- si la valeur est de type
result, c'est probablement à vous de le traiter - si c'est un autre type que vous récupérez, ça a déjà été géré ailleurs, la valeur a déjà été extraite et on a fait ce qu'on voulait de l'erreur
switch f() {
| Ok(x) => doSomethingWithValue(x)
| Error(err) => doSomethingWithError(err)
}
Là où ça devient très pratique pour des interfaces utilisateur, et on va prendre ici l'exemple de React, c'est qu'au lieu de maintenir des champs additionnels dans votre state pour afficher ou non une erreur (ce qui aura des chances de se désynchroniser par un oubli, puisque c'est votre responsabilité de le maintenir), vous pouvez stocker une valeur de type result dans l'état de vos composants, et l'exploser directement dans la fonction render pour en dériver ce que vous devez afficher :
setValue(_ => result)
// then
switch value {
| Ok(value) => <Success value />
| Error(error) => <ErrorMessage error />
}
Gérer les requêtes (aka le data-fetching)
Reprenons notre écran de chargement cassé :
À coup sûr, la structure choisie pour représenter l'état de leur requête est la suivante :
type state = {
isLoading: true | false,
error: error | null,
data: data | null
}
On a donc un objet avec trois propriétés (maintenues à la main) :
- est-ce que c'est en train de charger ?
- est-ce qu'on a reçu une erreur ?
- est-ce qu'on a reçu de la donnée ?
On se retrouve donc avec 2 états possibles par propriété.
Si on dresse un tableau des états qu'autorise cet objet, on se retrouve avec :
| isLoading | error | data | Is possible? |
|---|---|---|---|
FALSE | NULL | NULL | ✅ (Not asked) |
TRUE | NULL | NULL | ✅ (Loading) |
FALSE | ERROR | NULL | ✅ (Errored) |
FALSE | NULL | DATA | ✅ (Received data) |
TRUE | ERROR | NULL | ❌ |
TRUE | NULL | DATA | ❌ |
FALSE | ERROR | DATA | ❌ |
TRUE | ERROR | DATA | ❌ |
On a bien 4 cas légitimes qui représentent le cycle de vie de notre requête, mais également 4 autres états qui correspondent en pratique à rien, ou en tout cas à aucun état initialement prévu.
Pourquoi se retrouve-t-on avec 8 états possibles alors qu'on n'en avait prévu que 4 ?
C'est là que la notion de type algébrique intervient.
Pourquoi ça s'appelle comme ça ?
Tout bêtement parce qu'on a des types somme et des types produit, algébrique comme en mathématiques, "on fait de l'algèbre" avec les types :
- Les types somme, comme le type
optionqu'on a vu plus tôt, ont pour nombre d'états possibles la somme de leurs branches. Notre type option ne peut avoir que deux états,Some('a)ouNone. - Les types produit, comme notre objet représentant une requête, ont pour nombre d'états possibles le produit de leurs membres. Dans notre objet : 3 propriétés de 2 états chacune, 2 x 2 x 2 = 8 états en tout.
En modeling, visez toujours le minimum de nombre d'états autorisés. Cela vous évitera des bugs qui ne sont parfois pas évident à débusquer parce qu'on ne les a pas prévus, juste autorisés par erreur. Moins de combinatoire, moins de choses auxquelles réfléchir.
En partant de cette logique de réduction, on peut créer nous même un type somme pour représenter notre requête qui n'autorisera que les cas qui ont un sens pour nous.
- Je n'ai pas encore demandé au serveur
- Ça charge
- C'est fini
type asyncData<'value> =
| NotAsked
| Loading
| Done<'value>
Si la requête peut échouer, on peut stocker une boîte "result" à l'intérieur de l'état "J'ai fini de charger".
Ça nous donne un "j'ai fini de charger, et voilà le résultat, il contient soit une valeur soit une erreur"
asyncData<
result<'ok, 'error>
>
Le fait d'avoir cette représentation en type somme va nous permettre d'exploser très facilement notre boîte, parce que le nombre de cas à traiter est clairement délimité, et on n'a plus à tenter de le deviner à partir d'un objet complexe :
switch (resource) {
| NotAsked => ""
| Loading => "Loading ..."
| Done(Ok(value)) => "Loaded: " ++ value
| Done(Error(_)) => "An error occurred"
}
Pour aller plus loin sur les avatages de cette approche, n'hésitez pas à lire et cloner ce repository de démo qui contient un exemple simplifié illustrant les avantages à l'usage de types somme.
Conclusion
Les types ont souvent mauvaise presse, parce que dans beaucoup de langages ils servent principalement à dire au programme où stocker la valeur dans la RAM, et on les perçoit (à juste titre) comme une contrainte sans grand bénéfice.
Ce n'est pas le cas dans la plupart des langages fonctionnels, où ils sont un outil pour aider la personne qui programme. Ces langages et leurs approches évitent les erreurs évitables, et le font automatiquement, par nature.
Éviter ces erreurs abaisse la complexité accidentelle de votre code. Vous réduisez considérablement la nécessité de traiter des cas qui n'ont pas lieu d'exister, ce qui vous permet d'investir cette énergie dans le fait de créer de la complexité business, celle qui donne de la valeur à votre produit.
Follow up
La codebase front-end de BeOp, en ReScript, applique ces principes. Nous avons même open-sourcé quelques bibliothèques :
rescript-asyncdata, le type abordé un peu plus haut, dont on se sert pour représenter l'état de nos requêtes. La bibliothèque est accompagnée de quelques helpers.rescript-future, une alternative auxPromisepréférant déléguer au typeresultla gestion des erreurs, et apportant une gestion de l'annulation d'opérations.rescript-request, une bibliothèque permettant d'effectuer des requêtes, en les modélisant précisément afin d'éviter certains types d'erreurs.rescript-pages, le générateur de site statique responsable de générer le blog sur lequel vous vous trouvez, repose sur les trois bibliothèques au dessus !