This article is a translation for a talk given at the ParisJS meetup
→ The slides
→ The video (in French 🇫🇷) (56:44)
I imagine that the term "algebraic type" may frighten some, but we'll try to approach it from a more practical than theoretical angle.
Common UI issues

The image here is fairly well known, it is taken from Windows XP, where an error message proudly tells us "Success!".
We generally try to avoid this kind of strange behavior and we usually invest a lot of our energy in this, whether through tests, QA or other strategies.
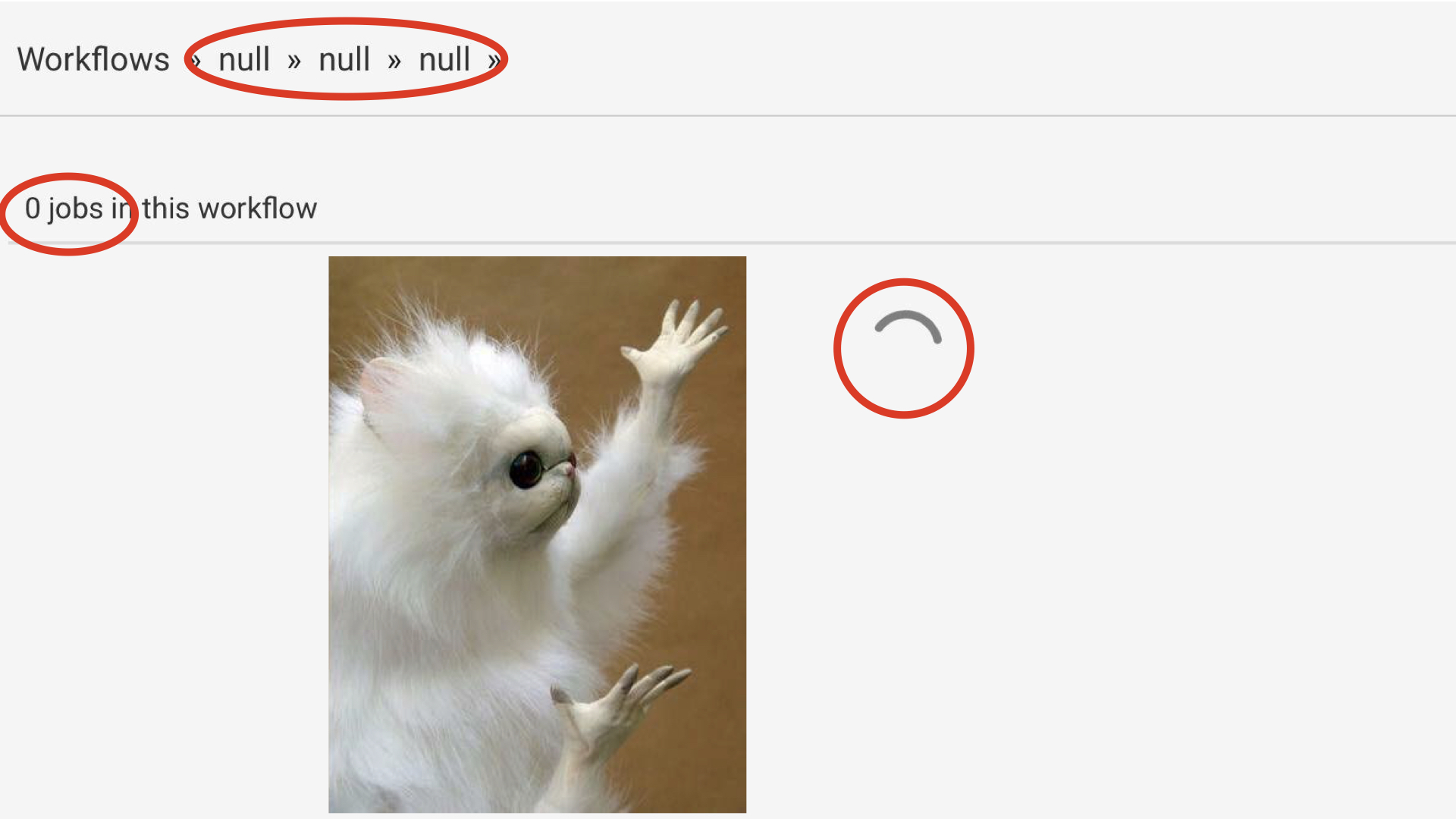
Yet these strange cases always come back.
If we look closely at this last screenshot, we're in a loading state (there is a loader), but we've got null displayed 3 times in the breadcrumb trail and 0 jobs in the summary. Yet when the loading ends, these values are replaced by the right ones.
What seems to happen is that not all the different blocks of the page have been warned that it was loading.
It may seem trivial, but it can also be symptomatic of a fairly serious problem: the information presented on the screen is wrong, rather than displaying "I don't know yet", it displays a false result. Imagine this kind of problem in an application used in a hospital, if during a long loading state you show that a patient receives 0 treatment, it can quickly influence poor decision-making for the doctors, and the software will be responsible for that.

Some fatal errors can also slip into your application, because of an oversight, an error in the code or an unforeseen case.
Most of the symptoms such as those we just saw come from the way we manage 3 things, and these 3 things are confronted with them in virtually any application with a user interface.
- Optionality: managing the presence or absence of a value
- Success: managing an operation that may fail
- Requests: fetching data that we don't have yet
Managing optionality
Take the example of a smartwatch that's in charge of tracking your physical activity. On the watch app on your smartphone, you have a view with a calendar that summarizes the recorded activity.
Let's assume that you are working on this application. The product team comes one day and tells you:
"We'd like to create a push notification to motivate users. The rule that seems good to us is to send it to people who in the last 30 days have:
→ a day or more without wearing their watch
→ a day or more with an activity below a certain threshold"
How convenient! To make your calendar you already have access to an array that contains the activity of the last 30 days.
In this array:
- Either you have an object with the data of the day
- Or you have
undefinedif the user didn't wear their watch
let last30daysActivity: array<maybeActivity>
// no activity recorded for the day
undefined
// some activity
type dayActivity = {
calories: int,
workoutDuration: int,
standUpHours: int,
}
We will therefore look in our array if an element matches the predicate we were given: we are looking for at least one empty day or one with low activity.
last30daysActivity.find(item =>
item == undefined || item.calories < 50
)
Then we run our first tests, and the call can return undefined. But what does undefined mean here?
Does that mean:
- that the
findmethod didn't find anything matching our predicate, in which case we shouldn't send a notification? - that the
findmethod found a maching empty day, in which case we need to send one?
Simply from the return value, we cannot know if we should send this notification.
To understand why we end up with this dilemma, we must look at the signature of the find method.
It takes an array of elements of type A, a predicate, and returns whether a type A element or undefined if no value satifies our predicate.
let find: (array<'a>, 'a => bool) => 'a | undefined
But if type A can include an undefined value, the return value can be undefined in two cases:
let find: (
array<'a | undefined>,
('a | undefined) => bool
) => 'a | undefined | undefined
// ^^^^^^^^^ ^^^^^^^^^
We have no way to distinguish the two cases. The two values are strictly identical. undefined and null replace the value if absent.
A correct way to identify the case we're in would be to use findIndex, which returns the match index, or -1 if none matches. From that index, we can them fetch manually the value in the array.
let index = last30daysActivity.findIndex(item =>
item == undefined || item.calories < 50
);
if(index == -1) {
// not found
} else {
let item = last30daysActivity[index];
if(item == undefined) {
// found day without recorded activity
} else {
// found day with low activity
}
}
That's quite a lot of branches in our code for a task that's supposed to be rather simple.
Most functional typed languages don't have undefined or null. They have an option (or maybe) type.
type option<'a> =
| Some('a)
| None
The option type is like a box. You can see this as Schrödinger's cat experiment: your box has two possible states, either it contains a value or it contains nothing.
Instead of carrying a value or its substitute, you carry a box that may contain a value.
Let's take the find equivalent in ReScript, it's called Belt.Array.getBy but the functionality is the same :
last30daysActivity->Belt.Array.getBy(item =>
switch item {
| None => true
| Some({calories}) when calories < 50 => true
| _ => false
})
If we look at the signature this time, we see that it returns an option value:
let getBy: (array<'a>, 'a => bool) => option<'a>
And when we replace the parameter with our optional values, we realize that instead of substituting the return value, we return an option option: we can store boxes in boxes.
let getBy: (
array<option<dayActivity>>,
option<dayActivity> => bool
) => option<option<dayActivity>>
In practice, this means that we can now distinguish precisely the meaning of the returned value, without imposing implementation details that unnecessarily complicate our code:
None // No match
Some(None) // Found an empty day
Some(Some(x)) // Found a filled day
Managing success (and failure)
In most languages, failures are often represented by exceptions, errors. We write functions that are supposed to return a result, and we will bypass execution when something fails.
Therefore, the signature of the function represents the case where everything goes well, the happy path.
// BE CAREFUL!!!
// Throws an error
let f: 'param => 'success;
On the other hand, knowing the cases of failure, unless you write annotations by hand or documentation, is immediately less obvious because the way to recover these errors is to wrap the code that may fail in a try/catch, at any level above the call that can "break".
This is not necessarily ideal, because it is often necessary to go and make the effort to see if the error is treated, and if so at what level of call stack it is.
try {
let x = f()
// The error might be thrown by `f`, but also from something
// `f` calls, somewhere
handleSuccess(x)
} catch(err) {
handleFailure(err)
}
For these cases, most typed functional languages again have an alternative called the result (or either) type.
type result<'ok, 'error> =
| Ok('ok)
| Error('error)
The result type is another kind of box, which this time contains either a result (or success value) or an error.
The huge advantage is that your function that may fail will return a box rather than a value directly. Just looking at the signature of the function, you know if it can fail:
let f: 'param => result<'success, 'error>;
And to extract the result that may be in the box, you are forced to manage the error case: no more surprise about where it is processed.
- if the value is of type
result, it's probably up to you to process it - if it's another type that you get, it's already been managed elsewhere, the value has already been extracted and we did what we wanted with the error
switch f() {
| Ok(x) => doSomethingWithValue(x)
| Error(err) => doSomethingWithError(err)
}
Where it becomes very convenient for user interfaces, and we'll take the example of React here, is that instead of maintaining additional fields in your state to display or not an error (which will likely be desynchronized by mistake, since there's a human responsibility to maintain it), you can store a result value in your component state, and explode it directly in the render function to derive what you need to display:
setValue(_ => result)
// then
switch value {
| Ok(value) => <Success value />
| Error(error) => <ErrorMessage error />
}
Managing requests (aka data-fetching)
Let's go back to our broken loading screen:
There's a fair chance the structure chosen to represent the status of their request looks like the following:
type state = {
isLoading: true | false,
error: error | null,
data: data | null
}
So we have an object with three properties (maintained by hand):
- is it loading?
- did we receive an error?
- did we receive some data?
We therefore end up with 2 possible states per property.
If we draw a table from the states this object allows, we end up with:
| isLoading | error | data | Is possible? |
|---|---|---|---|
FALSE | NULL | NULL | ✅ (Not asked) |
TRUE | NULL | NULL | ✅ (Loading) |
FALSE | ERROR | NULL | ✅ (Errored) |
FALSE | NULL | DATA | ✅ (Received data) |
TRUE | ERROR | NULL | ❌ |
TRUE | NULL | DATA | ❌ |
FALSE | ERROR | DATA | ❌ |
TRUE | ERROR | DATA | ❌ |
We do have 4 legitimate cases that represent our request lifecycle, but also 4 other states that mean nothing in practice, or at least to no state initially planned.
Why do we end up with 8 possible states when we had only planned 4?
This is where the notion of algebraic type comes in.
Why is it called that way?
Simply because we have sum and product types, algebraic as in mathematics, "we do algebra" with the types:
- Sum types, such as the
optiontype we saw earlier, have as many possible states as the sum of their branches. Our option type can only have two states,Some('a)orNone. - Product types, such as our object representing a query, have as many possible states the product of their members. In our object: 3 properties of 2 states each, 2 x 2 x 2 = 8 states in total.
In modeling, always aim for the minimum number of states allowed. This will avoid bugs that are sometimes not easy to find because they have not been predicted, just allowed by mistake. Less allowed states, fewer things to think about.
Starting from this reduction logic, we can create ourselves a sum type to represent our request that will only allow cases that make sense to us.
- I haven't asked the server yet
- It's loading
- It's done
type asyncData<'value> =
| NotAsked
| Loading
| Done<'value>
If the request can fail, a "result" box can be stored inside the "I finished loading" state.
It gives us a "I'm done, and that's the result, it contains either a value or an error"
asyncData<
result<'ok, 'error>
>
Having this representation in sum type will allow us to explode our box very easily, because the number of cases to be treated is clearly delimited, and we no longer have to try to guess it from a complex object:
switch (resource) {
| NotAsked => ""
| Loading => "Loading ..."
| Done(Ok(value)) => "Loaded: " ++ value
| Done(Error(_)) => "An error occurred"
}
To go further on the benefits of this approach, do not hesitate to read and clone this demo repository which contains a simplified example illustrating the advantages of using sum types.
Conclusion
Types often have bad press, because in many languages they are mainly used to tell the program where to store value in RAM, and they are perceived (rightly) as a constraint without much benefit.
This is not the case in most functional languages, where they are a tool to help the person who programs. These languages and their approaches avoid avoidable errors, and do so automatically, by nature.
Avoiding these errors reduces the accidental complexity of your code. You significantly reduce the need to deal with cases that do not exist, allowing you to invest this energy in creating business complexity, the one that gives value to your product.
Follow up
BeOp's front-end codebase, in ReScript, applies these principles. We have even open-sourced some libraries:
rescript-asyncdata, the type discussed above, which is used to represent the status of our requests. The library comes with some helpers.rescript-future, an alternative toPromisethat prefers to delegate success management toresult, and adding cancellation handling.rescript-request, a library for making requests, modeling them precisely to avoid certain types of errors.rescript-pages, the static site builder responsible for generating the blog you are on, is based on the three libraries above!